.jpg)
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
Blog categories



.webp)

Engineering Analytics
14
min
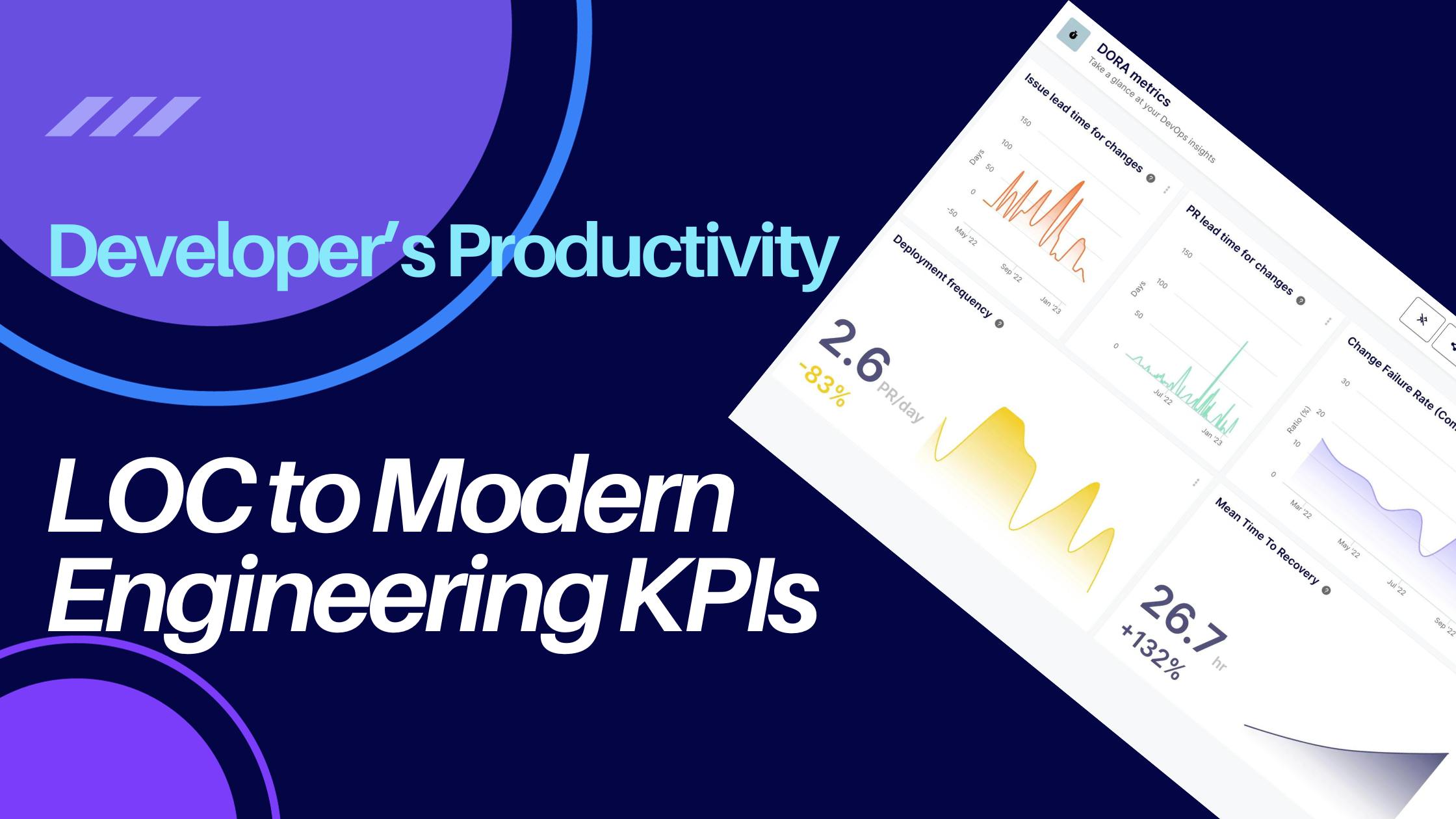
Software Velocity: How to Maximize Your Team Efficiency
•
November 23, 2023






.jpg)









.jpg)
.jpg)










.jpg)




.webp)




















.jpg)


.jpeg)

.jpeg)




.jpeg)













Development
4
min
Cloud Run and Cloud SQL - Avoid hitting Cloud SQL Admin connection quota
•
June 8, 2021





.jpeg)